Spoken Language Forensics & Informatics (SLFI) group
Speech Lab, LTRC, IIIT-Hyderabad
We extract signatures indicating how the spoken content was said? and use the signatures for robust spoken information retrieval
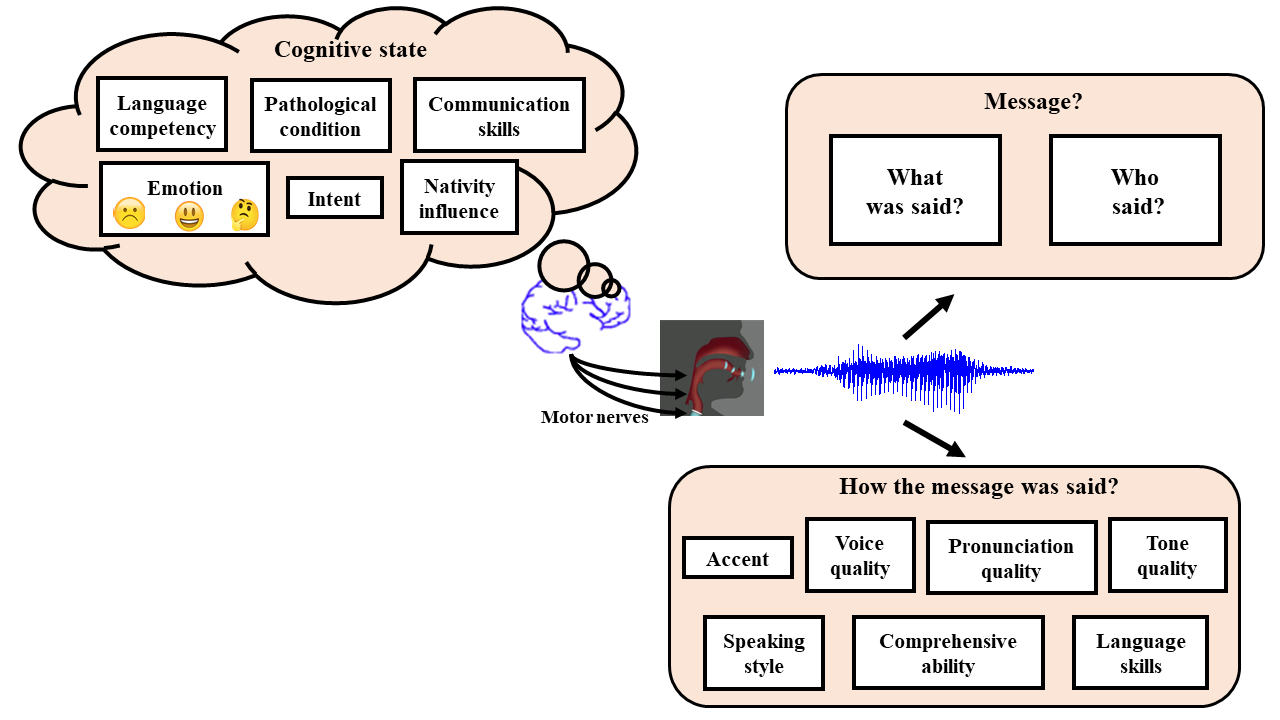
Our Objective
Our Works
Resource constrained non-native spoken error analysis (click here for the details)
Publications: We are working
Funding agencies:
Funding agencies:
Resource constrained prosodic analysis of non-native speech (click here for the details)
Publications: NCC 2021; Interspeech 2021
Funding agencies: KCIS Fellowship, IIIT Hyderabad;
Funding agencies: KCIS Fellowship, IIIT Hyderabad;
Automatic spoken data validation methods under non-native context (click here for the details)
Publications: We are working
Funding agencies: IHub-Data, IIIT Hyderabad;
Funding agencies: IHub-Data, IIIT Hyderabad;
Label Unaware Speech Intelligibility Detection and Diagnosis under Spontaneous Speech
(click here for the details)
Publications: We are working
Funding agencies: IHub-Data, IIIT Hyderabad;
Funding agencies: IHub-Data, IIIT Hyderabad;
Unsupervised approach for spoken grammatical error detection and correction under spontaneous conditions in the Indian context
(click here for the details)
Publications: We are working
Funding agencies: IHub Anubhuti, IIIT Delhi;
Funding agencies: IHub Anubhuti, IIIT Delhi;
Pronunciation assessment and semi supervised feedback prediction for spoken English tutoring
(click here for the details)
Publications: ICASSP 2016, 2017, 2018; Interspeech 2018, 2019; SLaTE 2019; Indicon 2018; Oriental COCOSDA 2019; Elseveir Speech Communication 2016; JASA 2018, 2019.
Funding agencies: DST; PM fellowship;
(click here for the details)
Publications: ICASSP 2016, 2017, 2018; Interspeech 2018, 2019; SLaTE 2019; Indicon 2018; Oriental COCOSDA 2019; Elseveir Speech Communication 2016; JASA 2018, 2019.
Funding agencies: DST; PM fellowship;
Automatic synthesis of articulatory videos from speech (click here for the details)
Publications: ICASSP 2018; Interspeech 2019.
Funding agencies:
Publications: ICASSP 2018; Interspeech 2019.
Funding agencies:
Our Tools